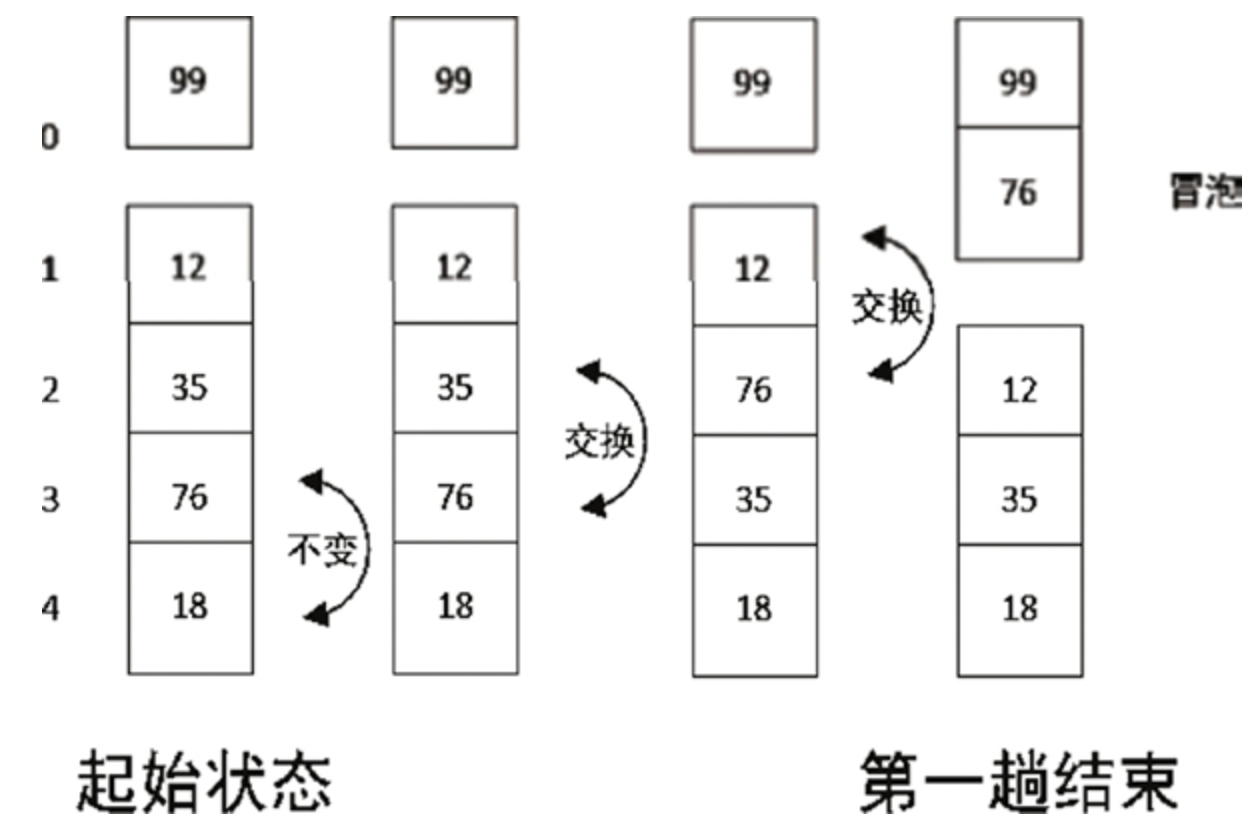
super()_super(props)
面试官:super() �?super(props) 有什么区别?
一、ES6 �?
�?ES6 中,通过 extends 关键字实现类的继承,方式如下�?
1 | class sup { |
在上面的例子中,可以看到通过 super 关键字实现调用父类,super 代替的是父类的构建函数,使用 super(name) 相当于调�?sup.prototype.constructor.call(this,name)
如果在子类中不使�?super,关键字,则会引发报错,如下�?
报错的原因是 子类是没有自己的 this 对象的,它只能继承父类的 this 对象,然后对其进行加�?
�?super() 就是将父类中�?this 对象继承给子类的,没�?super() 子类就得不到 this 对象
如果先调�?this,再初始�?super(),同样是禁止的行�?
1 | class sub extends sup { |
所以在子类 constructor 中,必须先代�?super 才能引用 this
二、类组件
�?React 中,类组件是基于 ES6 的规范实现的,继�?React.Component,因此如果用�?constructor 就必须写 super() 才初始化 this
这时候,在调�?super() 的时候,我们一般都需要传�?props 作为参数,如果不传进去,React 内部也会将其定义在组件实例中
1 | // React 内部 |
所以无论有没有 constructor,在 render �?this.props 都是可以使用的,这是 React 自动附带的,是可以不写的�?
1 | class HelloMessage extends React.Component { |
但是也不建议使用 super() 代替 super(props)
因为�?React 会在类组件构造函数生成实例后再给 this.props 赋值,所以在不传�?props �?super 的情况下,调�?this.props �?undefined,如下情况:
1 | class Button extends React.Component { |
而传�?props 的则都能正常访问,确保了 this.props 在构造函数执行完毕之前已被赋值,更符合逻辑,如下:
1 | class Button extends React.Component { |
三、总结
�?React 中,类组件基�?ES6,所以在 constructor 中必须使�?super
在调�?super 过程,无论是否传�?props,React 内部都会�?porps 赋值给组件实例 porps 属性中
如果只调用了 super(),那�?this.props �?super() 和构造函数结束之间仍�?undefined